python的json模块
什么是序列化和反序列化?
序列化 在分布式环境下,无论是何种数据,都会以二进制序列的形式在网络上传输。序列化是一种将对象以一连串的字节描述的过程,用于解决在对对象流进行读写操作 时所引发的问题。序列化可以将对象的状态写在流里进行网络传输,或保存在文件、数据库里,并在需要时把该流读取出来重新构造一个相同的对象。 反序列化 就是将流转为对象。
json
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flatte ning等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里 称之为反序列化,即unpickling。
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可 以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
介绍使用四个方法
json.dumps() json.dump() json.loads() json.load()
一般存储数据的方法
在介绍之间我们先说一下,当我们在存储数据的时候,一定要是字符串的类型才能存储。
下面是一个简单的存数据的程序
dic={"name":"linlin"}#将字典类型转为字符串类型data1=str(dic)f1=open('file1','w')#存入数据f1.write(data1)f1.close()
取出数据
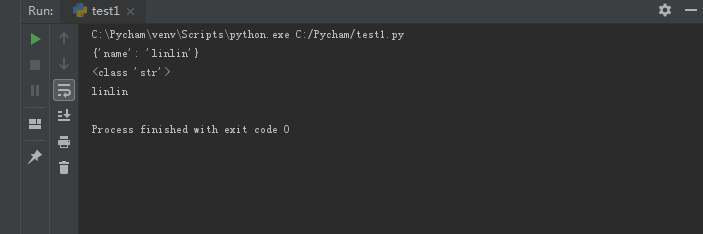
f2=open('file1','r')data2=f2.read()print(data2)print(type(data2))data2=eval(data2)print(data2['name'])f2.close()
运行结果
我们从文件取出来,如果不使用eval函数,取出来还是字符串类型,就不能直接根据键名来使用键值
eval内置方法可以将一个字符串转成python对象
eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候, eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
json.dumps()与json.loads()
用于数据交换和文件操作
import jsondic={"name":"linlin"} #转为json字符串,序列化data1= json.dumps(dic) #存数据f=open('filename','w')f.write(data1)f.close()#取数据f=open('filename','r') #反序列化data2=json.loads(f.read())f.close()
json.dump()与json.load()
只适用于文件操作
import jsondic={"name":"linlin"} #取数据f=open('filename','w') #序列化数据+自动存放数据json.dumps(dic,f) #存数据f=open('filename','r') #反序列化数据+自动取出数据json.load(f)